
About me
I am now an Associate Professor in the School of Computer Science and Engineering at Southeast University.
Before that, I worked as a postdoctoral researcher at The University of Hong Kong, working with Prof.Ping Luo. Berfore that, I obtained my bachelor’s and doctoral degrees at Beihang University, supervised by Prof.Jun Zhang and Prof.Xianbin Cao. During my Ph.D. studies, I was extremely fortunate to receive guidance from Prof.Xiaoyan Luo and Prof.Jungong Han.
I am currently a master’s supervisor at Southeast University. If you are interested in join my group for master degree, please read the To Prospective Student below. Meanwhile, the Research internships for outstanding undergraduate students are also welcome.
Contact me with: huyutao AT seu dot edu dot cn (or) huyutao_0910 AT 163 dot com.
Research:
Our group focuses on the challenges of computer vision and large models in real-world applications (e.g., precision medicine, intelligent transportation, remote sensing), mainly on accurate recognition under complex imaging conditions, including image quality enhancement, large-model-assisted data annotation, and fine-grained feature extraction. Specifically, I am interested in the following topics:
- Multi-modal learning with RGB images, textual description, hyperspectral images, infrared image, etc.
- Artificial intelligence and computer vision for medical, especially about (multi-modal) pretrain, multi-modal learning.
To Prospective Student:
If you are interested in joining my group for master degree, please fell free to contact with me with your resume.
- Make sure you read this document before sending emails.
🔥 News
- 2024.02: 🎉 One paper is accepted by CVPR2024
- 2023.09: 🎉 One paper is accepted by Pattern Recognition
- 2023.07: 🎉 One paper is accepted by ICCV2023
📝 Selected Publications
For my full publication list, please go to my google scholar profile
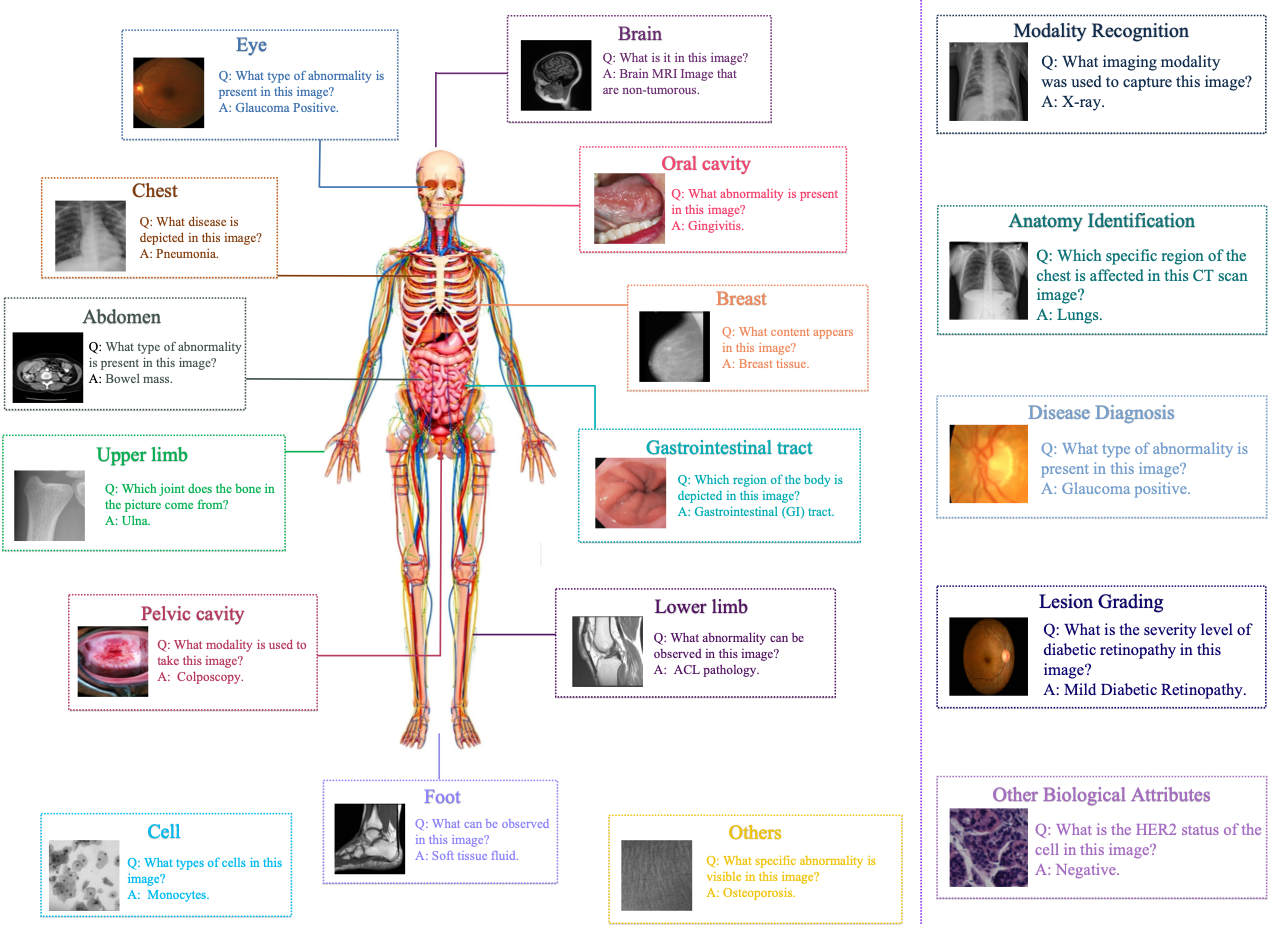
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
- We propose OmniMedVQA, a large-scale and comprehensive Visual Question Answering benchmark tailored to the medical domain. OmniMedVQA contains 12 different modalities and covers more than 20 unique human anatomical regions, establishing a comprehensive benchmark for evaluating the fundamental capabilities of LVLMs in addressing medical challenges.
- We conduct a thorough evaluation for 12 different LVLMs, including 8 general-domain LVLMs and 4 specialized LVLMs designed for medical applications. As far as we know, it is currently the most comprehensive evaluation of LVLMs towards the medical domain.

Beyond One-to-One: Rethinking the Referring Image Segmentation
Yutao Hu, Qixiong Wang, Wenqi Shao, Enze Xie, Zhenguo Li, Jungong Han, Ping Luo
- We find the deficiency of referring image segmentation when meeting the one-to-many and one-to-zero text inputs, which strongly limits the application value in real-world scenarios.
- We collect a new challenging dataset, termed as RefZOM, in which the text inputs are not limited to the one-to-one setting. The proposed dataset provides a new perspective and benchmark for future research.
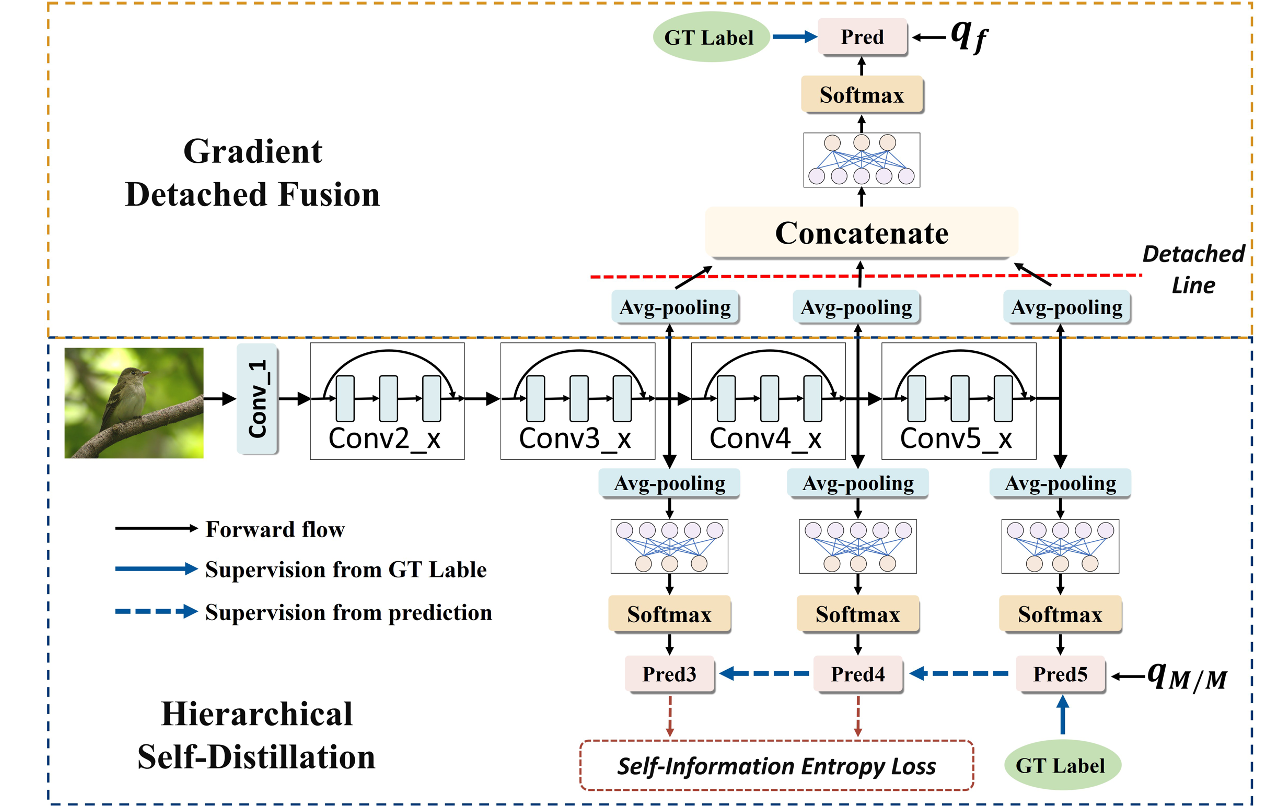
Hierarchical self-distilled feature learning for fine-grained visual categorization
Yutao Hu, Xiaolong Jiang, Xuhui Liu, Xiaoyan Luo, Yao Hu, Xianbin Cao, Baochang Zhang, Jun Zhang
- We rethink the efficacy of deep supervision in FGVC and propose a new learning framework, termed HSD, in which the prediction from the next block is utilized as the soft labels for the previous one. By doing so, overstrict supervision, which has been proven detrimental to FGVC, is avoided in the intermediate supervision.
- We design a distillation strategy with dynamic temperature adjustment. In our HSD, instead of using the hyperparameter (temperature T) to produce the soft label, we employ SIELoss to regularize each prediction, which not only drives each layer to deliver soft labels adaptively but also improves the generalization ability of the network.
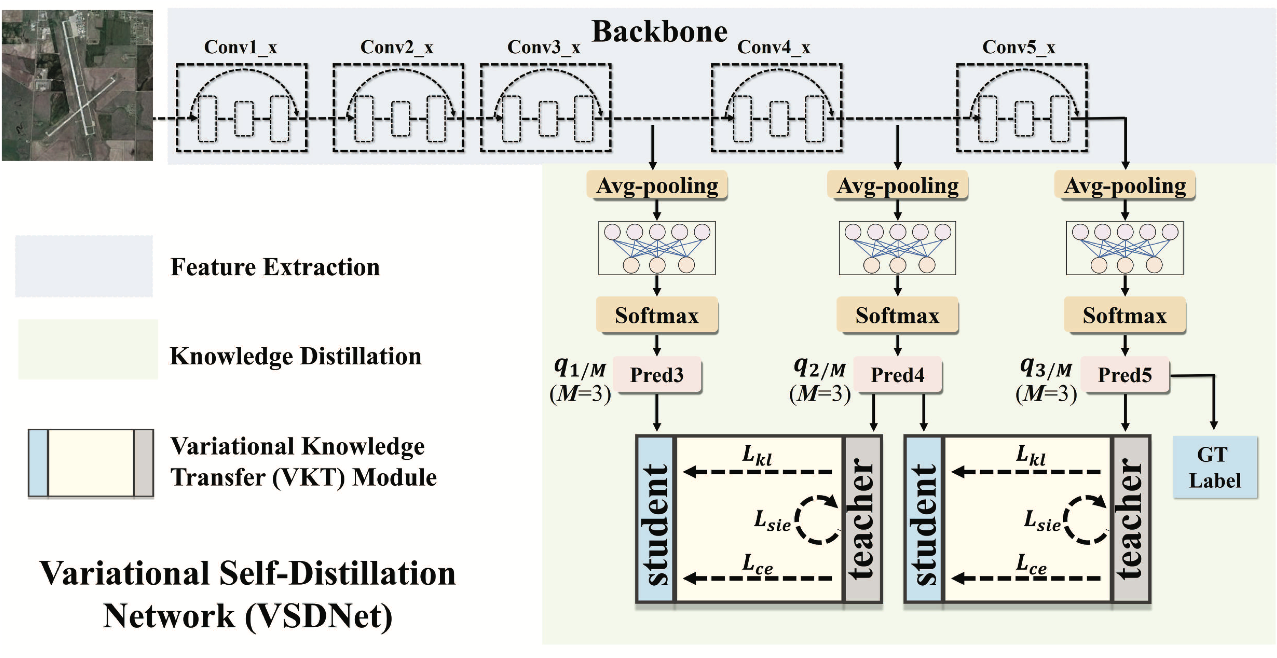
Variational self-distillation for remote sensing scene classification
Yutao Hu, Xin Huang, Xiaoyan Luo, Jungong Han, Xianbin Cao, Jun Zhang
- We propose Variational Self-Distillation Network (VSD-Net) to adaptively exploit class entanglement information and hierarchically distill it from the deep layers into the shallow parts. In this way, besides the category information, more fine-grained information is provided in the training, contributing to discriminative feature learning.
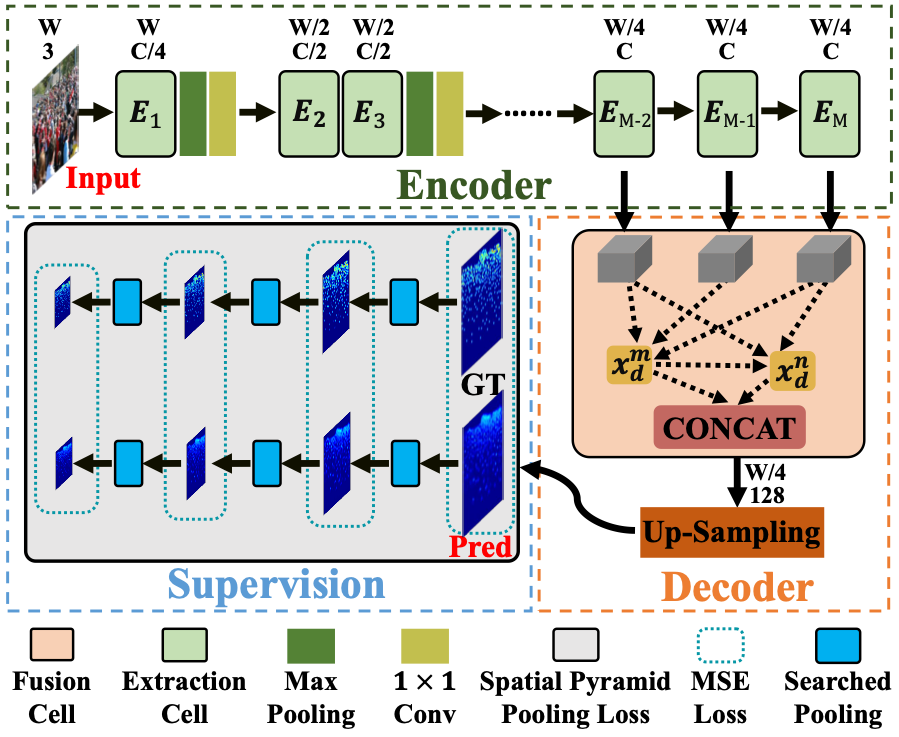
Nas-count: Counting-by-density with neural architecture search
Yutao Hu, Xiaolong Jiang, Xuhui Liu, Baochang Zhang, Jungong Han, Xianbin Cao, David Doermann
- To our best knowledge, NAS-Count is the first attempt at introducing NAS for crowd counting, where a multi-scale architecture is automatically developed to address the scale variation issue.
- A counting-specific two-level search space is developed in NAS-Count, from which a multi-path encoder-decoder architecture (AMSNet) is discovered efficiently with a differentiable search strategy using stochastic gradient descent (SGD)
- scale Pyramid Pooling Loss (SPPLoss) is searched automatically to improve MSE supervision, which helps produce the higher-quality density map via optimizing structural information on multiple scales
📖 Educations
- 2017.09 - 2022.06, Ph.D., Beihang Univeristy.
- 2013.09 - 2017.06, Undergraduate, Beihang Univeristy.
💻 Work Experiences
- 2022.07 - now, Postdoctoral Researcher, The University of Hongkong.